내가 아는 파이썬의 특징 중 GIL만큼 신기한 특징도 없다.
파이썬에서 하나의 스레드에 모든 자원을 할당하고 다른 스레드에서 접근할 수 없도록 Lock을 건다. OS 공부하며 본 그 뮤텍스와 똑같다.
이번 포스팅은 Python, Java 두가지 언어로 Single, Multi Thread 각각의 상황에서 무거운 연산을 진행하며 시간을 측정하고 시간 차이를 통해 GIL을 확인해보고 GIL의 존재 이유를 설명하려 한다.
들어가기에 앞서 현재 내 컴퓨터 환경은 아래와 같다.

JDK 8.0, pypy 3.10 을 사용했다.
멀티 스레드 연산 실험
실험은 1 ~ 2000000000(20억)의 값을 더하는 속도를 비교할 것이다.
멀티스레드 환경, 단일 스레드 환경의 연산속도를 Java와 Python에서 각각 비교해보겠다.
Java에서 단일스레드
비교를 위한 자바에서의 연산 실험이다.
먼저 단일 스레드에서의 연산을 실험할 코드는 아래와 같다.
/**
* 단일 스레드에서의 연산
* sum : 1~20억을 더한 결과값
*/
long start = System.currentTimeMillis();
long sum = 0;
for(int i =0; i < 2000000000; i++) {
sum+=i;
}
long end = System.currentTimeMillis();
System.out.println("Thread");
System.out.println("연산 시간 : " + (end-start)/1000.0 +"초");
System.out.println("result : " + sum);
내 훌륭한 노트북은 자바, 단일스레드로 1부터 20억까지 더하는데 0.68초가 걸리는걸 확인했다.
Java에서의 멀티스레드
다음은 멀티 스레드에서의 연산을 실험할 코드이다.
/*
* sum (long) : 1부터 20억을 더한 결과
* start(int) : 나누어진 구간의 시작
* end (int) : 나누어진 구간의 끝
*/
public class MyThread extends Thread{
public static long sum;
private int start;
private int end;
public MyThread(int start, int end) {
this.start = start;
this.end = end;
}
/**
* start ~ end의 값을 모두 더함
*/
@Override
public void run() {
long temp = 0;
for(int i = start; i <= end ; i ++) {
temp+=i;
}
sum+=temp;
}
}/**
* 멀티스레드에서의 연산
* target(int) : 1부터 더할 범위의 수 == 20억
* tharedCnt(int) : 사용될 스레드의 수
* MyThread[] : 스레드를 담을 변수.
* Thread.start() : Thread에서 Thread.run()을 호출함 -> 각 스레드에 할당된 범위를 더
* Thread.join() : Thread가 종료될때까지 기다릴때 사용
*
*/
start = System.currentTimeMillis();
int threadCnt = 8;
int target = 2000000000;
MyThread[] threads = new MyThread[threadCnt];
for(int i = 0 ; i < threads.length; i++) {
threads[i] = new MyThread(i*(target/threadCnt), (i+1)*(target / threadCnt)-1);
threads[i].start();
}
for(int i = 0 ; i < threads.length; i++) {
threads[i].join();
}
end = System.currentTimeMillis();
System.out.println("Multi Thread");
System.out.println("연산 시간 : " + (end-start)/1000.0 +"초");
System.out.println("result : " + MyThread.sum);각 쓰레드는 20억에서 threadCnt개의 범위를 나누어 할당받은 후 static으로 선언된 MyThead.sum의 값에 더하게 된다. 중요한건 결과니깐 결과를 보자.
0.68초 -> 0.232초로 빨라졌다.
전체 코드
public class MultiThread {
public static void main(String[] args) throws InterruptedException {
/**
* 단일 스레드에서의 연산
* sum : 1~20억을 더한 결과값
*/
long start = System.currentTimeMillis();
long sum = 0;
for(int i =0; i < 2000000000; i++) {
sum+=i;
}
long end = System.currentTimeMillis();
System.out.println("Thread");
System.out.println("연산 시간 : " + (end-start)/1000.0 +"초");
System.out.println("result : " + sum);
/**
* 멀티스레드에서의 연산
* target(int) : 1부터 더할 범위의 수 == 20억
* tharedCnt(int) : 사용될 스레드의 수
* MyThread[] : 스레드를 담을 변수.
* Thread.start() : Thread에서 Thread.run()을 호출함 -> 각 스레드에 할당된 범위를 더
* Thread.join() : Thread가 종료될때까지 기다릴때 사용
*
*/
start = System.currentTimeMillis();
int threadCnt = 8;
int target = 2000000000;
MyThread[] threads = new MyThread[threadCnt];
for(int i = 0 ; i < threads.length; i++) {
threads[i] = new MyThread(i*(target/threadCnt), (i+1)*(target / threadCnt)-1);
threads[i].start();
}
for(int i = 0 ; i < threads.length; i++) {
threads[i].join();
}
end = System.currentTimeMillis();
System.out.println("Multi Thread");
System.out.println("연산 시간 : " + (end-start)/1000.0 +"초");
System.out.println("result : " + MyThread.sum);
}
}
/*
* sum (long) : 1부터 20억을 더한 결과
* start(int) : 나누어진 구간의 시작
* end (int) : 나누어진 구간의 끝
*/
public class MyThread extends Thread{
public static long sum;
private int start;
private int end;
public MyThread(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public void run() {
long temp = 0;
for(int i = start; i <= end ; i ++) {
temp+=i;
}
sum+=temp;
}
}
Python에서의 단일스레드
정확히는 Pypy를 사용했다. 파이썬의 경우 20억까지 더하는데 예상보다 더 걸린다... pypy는 JIT 컴파일러를 사용하는데 jvm도 JIT 컴파일러를 쓴다. JIT 컴파일러에 대해서는 다음에 자세히 포스팅하기로 하고 아무튼 반복문, 함수 등에 대해 최적화 해주는 친구라고 생각하자.
# start부터 end까지 result에 더해주는 함수
def work(start: int,end: int) -> None:
global result
for i in range(start,end):
result += i멀티 스레드, 단일스레드도 이 함수를 사용해서 실험한다.
단일 스레드의 코드는
result = 0
start_time = time.time()
work(1,2000000000)
end_time = time.time()
print("Single-Thread")
print(f"연산 시간: {(end_time-start_time)/1000}")
print(f"result: {result}")
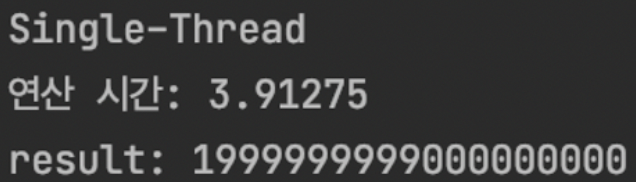
결과는 위와 같다.
Python에서의 멀티스레드
똑같이 작성해놓은 work 함수를 사용할 것이다.
result = 0
start_time = time.time()
threads = []
thread_cnt = 8
target = 2000000000
for i in range(thread_cnt):
threads.append(threading.Thread(target=work(i * (target // thread_cnt), (i + 1) * (target // thread_cnt))))
threads[-1].start()
for t in threads:
t.join()
end_time = time.time()
print("Multi-Thread")
print(f"연산 시간: {(end_time-start_time)/1000}")
print(f"result: {result}")자바에서 멀티스레드와 동일한 로직으로 동작한다.
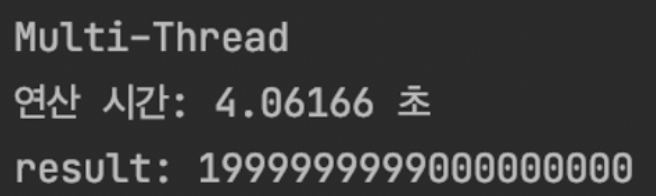
결과는 위와 같다.
3.9 -> 4.0초로 더 느려졌다. 자바에서의 결과와 반대로 더 느려졌다.
결과

자바는 빨라졌지만, 파이썬은 멀티스레드 환경에서 오히려 더 느려졌다.
GIL - Global Interpreter Lock
앞에서 말했지만 파이썬의 경우 하나의 스레드에 자원을 할당하고 Lock을건다. 즉 파이썬 인터프리터는 하나의 스레드만 하나의 바이트 코드를 실행 시킬 수 있다.
코어가 8개인 환경에서 스레드 8개가 작업을 한다고 가정해보자.
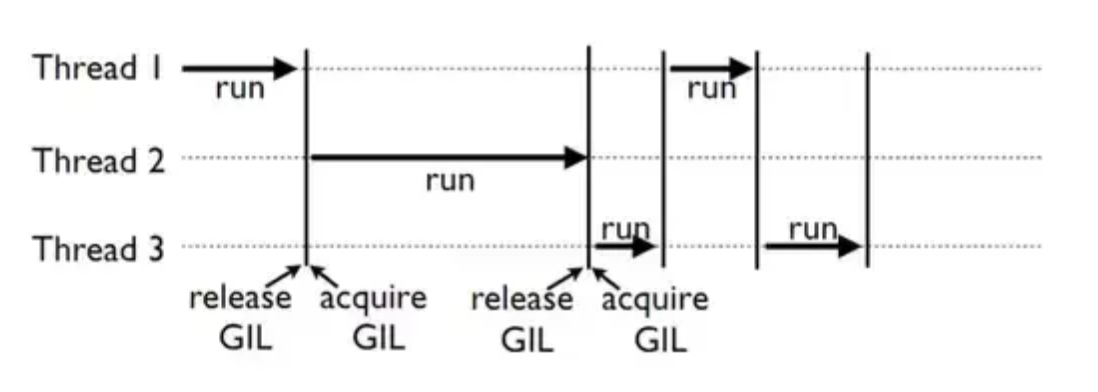
000,000,000~250,000,000 까지 더하는 스레드
250,000,001~500,000,000 까지 더하는 스레드
500,000,001~750,000,000 까지 더하는 스레드
...
1,750,000,000 ~ 2,000,000,000 까지 더하는 스레드
파이썬의 경우 각 스레드는 위 그림과 같이 동작한다. 실험에 빗대어 보면 단일스레드가 3.8초 동안 연산한걸, 8개의 스레드가 4.06초동안 번갈아가며 연산한다. 오히려 context switch에 비용이 추가적으로 발생하며 싱글스레드보다 느린 결과를 보여준다. 자바의 경우엔 이 모든 스레드가 0.232초 사이에 동시에 동작하며 단일 스레드 연산 시간인 0.677초보다 빠르게 해결할 수 있다.
왜 귀도 반 로섬씨는 이런 비효율적으로 보이는 락을 만들었을까.
파이썬은 문자열부터 정수, 실수, 뭐 죄다 객체다. 심지어 함수도 객체다.
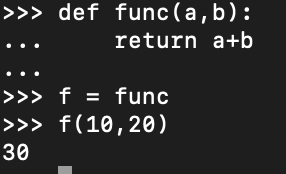
그래서 위 사진처럼 함수도 변수에 저장할 수 있고, 매개변수로도 넘길 수 있다. (이걸 어따쓰냐 궁금하다면.. Decorator 등 한 번 알아봐라)이렇게 모든게 객체인 파이썬은 문제가 조금 있다. 바로 메모리 관리다.
Call By Value랑 Call By Reference도 헷갈려했던 기억이 있는데 파이썬은 Call By Object-reference라는 호출 방식을 사용하고, 알아보니 또 헷갈려 죽으려하는 내가 보인다. 이렇게 헷갈리는데 모든게 객체다. 이때 사람이 메모리 할당과 해제를 직접 한다면 파이썬이 이렇게까지 인기를 끌 수 없었을거다. 아무튼 귀도반로섬씨께서는 메모리 관리 방법으로 reference counting을 사용했다. 예를들면 a = 999라는 코드라면 999라는 객체의 reference counting은 1이다. 이때, 특정 객체를 참조하는 변수의 개수가 0이라면 메모리에서 해제하면 되는데 몹시 간단하고 직관적이다. 물론 단일스레드에서의 얘기다.
멀티스레드 환경에서 reference counting은 critical section으로 여러 스레드가 이 영역에 진입하게 되면 Race Condition으로 동기화 문제가 발생한다. 그 결과 값을 참조하고 있음에도 불구하고 reference counting이 0이 되어 메모리에서 삭제될 수도 있고, 아무도 참조를 안하고 있음에도 메모리에 남아있을수도 있다!(파이썬에선 GIL때매 있을 수 없는 상황이으로 극단적인 예시이며 순환참조의 경우는 GC가 세대별로 확인하며 열심히 지울거다.)
어떻게 reference counting의 동기화 문제를 해결할까 고민하던 귀도반로섬은 문제 자체를 뿌리뽑았다. 바로 Race Condition이 일어날 환경자체를 막았다. 파이썬 전체적으로 적용될 뮤텍스를 하나 만들었고 이름은 GIL이라 붙였다! 물론 "아 머리 아프다. 그냥 막아 ㄱㄱ." 이런 판단은 아니다. 동기화를 위해 파이썬 코드의 수 많은 객체와 객체들 간 연산에서 일일히 Lock을 걸어주는것보다 GIL을 사용하는 방법이 훨씬 적은 비용으로 처리할 수 있다. 만약 각각의 객체가 Lock을 갖고 thread-safe하게 만든다면 그 어떤 천재가 와서 코딩해도 DeadLock을 마주하고 "이게 왜 안돼" 하다가 GIL을 만들었을거다.
그럼 파이썬을 쓰면 멀티 스레드 환경을 고려 안해도 될까?
물론 아니다. 기본적으로 GIL은 CPU-bound 작업에 한해 Lock을 건다. Sleep, I/O-bound(입출력, File, DB, Network)에서는 GIL이 적용되지 않는다. 따라서 I/O작업( 네트워크 요청 DB액세스 등)을 수행할때는 멀티 스레딩이 성능적으로 이점을 얻을 수 있다. 그러나 일반적인 I/O 이벤트를 보면 이벤트를 처리하는 비용보다는 이벤트가 발생하기까지 기다리는 비용이 크기때문에 멀티 스레드 보다는 비동기 프로그래밍을 사용하는게 성능적으로 이점을 얻는 경우가 많다.
CPU-bound의 작업을 수행하는 경우에는 멀티스레드 보다는 멀티프로세스 혹은 다른 병렬처리 방식을 고려해야 한다. 이때 파이썬은 multiprocessing이나, 비동기 작업을 처리하기위한 asyncio와 같은 라이브러리를 제공한다. 싱글 스레드에서 비동기로 작업하기 는 다음에 포스팅하겠다 !.
Java는 GIL이 없는데..
Java는 GIL없이 어떻게 메모리를 자동으로 관리하고 있을까?
파이썬은 Reference Counting을 사용하는 것과 달리 자바에서는 기본적으로 Garbage Collection을 Mark and Sweep 방식으로 관리한다. (JDK 8기준)
간단하게 설명하면 jvm의 heap 메모리에는 Eden, Survive0, Survive1, Old 영역이 존재한다. 가장 처음 객체가 할당되면 Eden으로, Eden 영역에 메모리가 다 차면 모든 스레드를 일시 정지(Stop-the-world)한 뒤 root객체로 부터 접근 가능한 객체들을 마킹(Mark)하고, 마킹되지 않은 객체는 전부 메모리를 해제(Sweep)한다. 이게 Mark-and-sweep이다. 여기서 마킹된 객체는 살아 남아 survive0 영역으로 이동되며 해당영역까지 가득 찰 경우 다시 한 번 Mark-and-sweep을 진행하고 살아남은 객체는 다른 survive영역으로 이동한다. 일정 횟수의 mark-and-sweep에서 살아남으면 Old 영역으로 넘어가게 된다.
Reference Counting 방식은 메모리를 해제하기 위해 객체의 참조가 변경 될 때마다 Critical Section에 진입을 막으며 Atomic한 연산을 수행해야하지만, Mark-and-sweep은 메모리가 가득 찼을때 메모리를 해제하기 때문에 Lock이 필요가 없다. 내비뒀다가 한 번에 해제하기 때문이다. 하지만 마킹을 위해 모든 스레드를 일시정지(Stop-The-world)하는 과정이 존재하고, 객체 소멸 시점을 예측하기도 어렵다는 단점이 있다.(모든 스레드가 일시정지 되는 시점을 예측하기 힘들다.)
실험하다가 만난 문제가 많다..
pypy가 실제 동작하는거에 비해 연산시간이 짧게 나오는가 하면 Python은 그냥 하염없이 기다려야했다.
- python의 time.time은 sec를 반환하고 java는 milisec을 반환하기때문에 단위를 맞췄다. "파이썬 빠르네 !" 하고 좋아했다가 아차 싶었다. ㅎㅎ;
Integer Interning과 Integer Caching
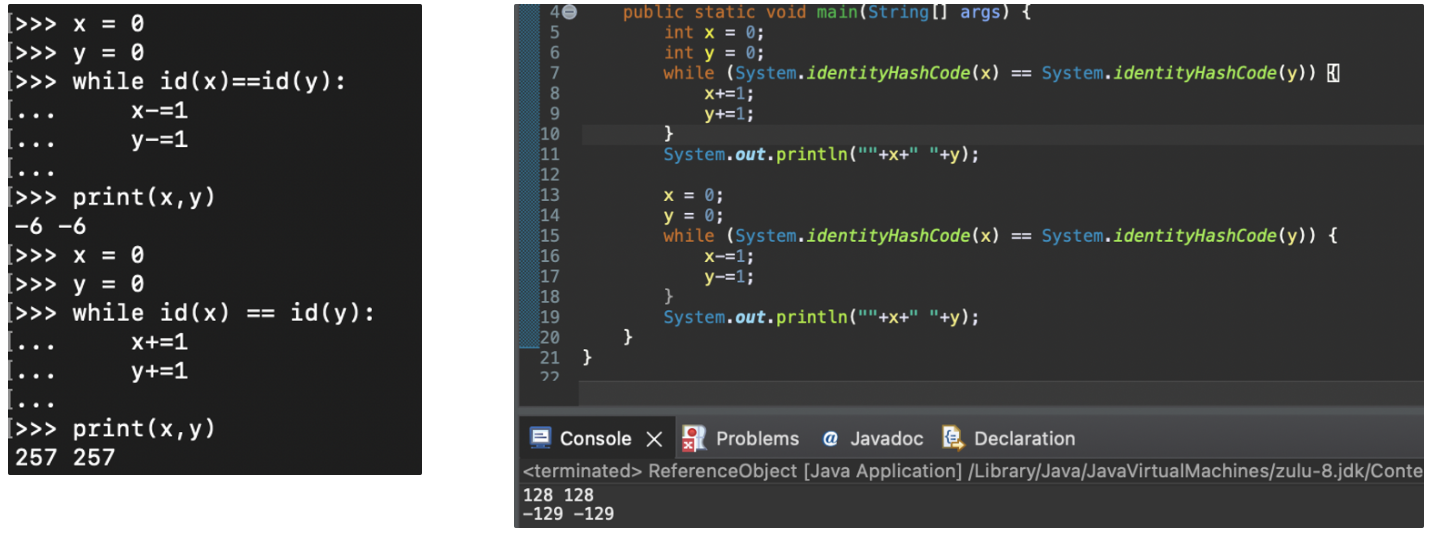
"파이썬은 모든게 객체다." 라고 말하면서 -5~256의 값을 미리 할당해놓고 쓴다는걸 보여주고, 자바와 차이를 보여주려했다. 자바는 미리 할당하지 않는다고 생각했기 때문이다.
그런데 이게 왠걸 자바도 -128~127의 값은 같은 주소값을 바라보고 있었다.
얘넨 이런짓을 왜할까 - 정수 인터닝과 정수 캐싱
파이썬의 경우에는 "정수 인터닝 (Integer Interning)" 이라는 최적화 기법이며 작은 정수값은 자주 사용된다는 가정하에 정수객체를 미리 할당하고 지속적으로 재사용하는 방식을 채택했다. 미리 생성하여 캐시에 저장해두고, 동일한 정수 값에 대해 해당 정수 객체를 가리키도록 하며 재사용한다. 이는 정수 객체를 생성하고 해제하는 비용을 줄이고 메모리를 절약할 수 있다.
자바의 경우에는 정수 인터닝과는 조금 다른 "정수 캐싱 (Integer Caching)"을 수행한다. 자세히 말하자면 자바는 Byte, Short, Integer, Long 등의 정수 래퍼 클래스에서, 범위가 -128~127까지인 정수 값에 대해 "정수 캐싱"을 수행한다. 이또한 작은 정수값에 대해 객체를 재사용함으로써 메모리를 절약하고 성능을 향상시키는 것을 목적으로 한다.